
Web crawlers, also known as spiders, bots or robots, are programs that systematically browse and index the web by crawling from one web page to another and gathering information. They play a vital role in search engines, as they are responsible for finding and indexing web pages so that users can search for information efficiently.
In this comprehensive guide, we will dive deep into understanding what web crawlers are, how they work, their types, key functions, and more. Let’s get started!
What are Web Crawlers?
A web crawler is an automated program or script that methodically scans or crawls through internet pages to create an index of the data it finds. The main goal of web crawlers is to gather information and bring value to users.
The crawling process starts with a list of URLs or web page addresses that serve as the starting points. The bot then visits these pages, extracts information like text, images, links, metadata, etc. and adds this data to a search engine’s index. It also gathers all the hyperlinks on each page to add new URLs to the crawling queue. This cycle continues as the bot recursively crawls across the expanse of the web.
In short, web crawlers are the worker bees of search engines that tirelessly comb through websites to aggregate data that enables users to search the internet efficiently. Without them, search engines would be useless.
Key Functions of a Web Crawler
The primary functions of a web crawler include:
- Website Discovery – Crawl across websites to discover new URLs and web pages. This expands the search engine’s index coverage.
- Indexing – Extract and store information from websites in a search engine’s database. This powers search results.
- Updating – Revisit indexed pages periodically to check for changes and keep data fresh.
- Metadata Extraction – Gather metadata like page titles, descriptions, keywords, etc. to understand page content.
- Link Analysis – Follow links between pages to chart website structure and relationships. This helps improve search relevancy.
- Traffic Estimation – Estimate website popularity metrics like visitors, page views based on crawl frequency.
- Site Mapping – Create a site map to display the website’s page structure and hierarchy visually.
- Feed Discovery & Indexing – Find and index syndicated feeds like RSS/Atom to surface fresh content.
- Error Checking – Identify broken links, 404 errors, etc. to inform webmasters.
How Do Web Crawlers Work?
The web crawling process involves several steps:
1. Crawl Starting Points
The crawler initiates its journey from a predefined list of seed URLs or web addresses. For major search engines, this list contains millions of starting points.
2. Fetch Web Page Content
The bot downloads the HTML content along with other elements like images, videos, CSS, JavaScript, etc. of the seed URLs.
3. Parse Page Content
The crawler parses through the downloaded content to extract vital information like text, titles, metadata, links, media, etc. using data extraction techniques.
4. Index Page Data
The extracted data is formatted and indexed into the search engine’s database. This powers search results.
5. Analyze Outbound Links
The crawler scans the page for outbound links and adds them to the crawling queue as new URLs to visit.
6. Revisit Pages Periodically
Crawlers revisit indexed pages regularly to check for changes and keep the search engine index fresh. The frequency depends on factors like page importance and update history.
7. Crawl Again
The bot picks the next URL in queue and repeats the crawling cycle until all links are crawled exhaustively to the maximum crawl depth.
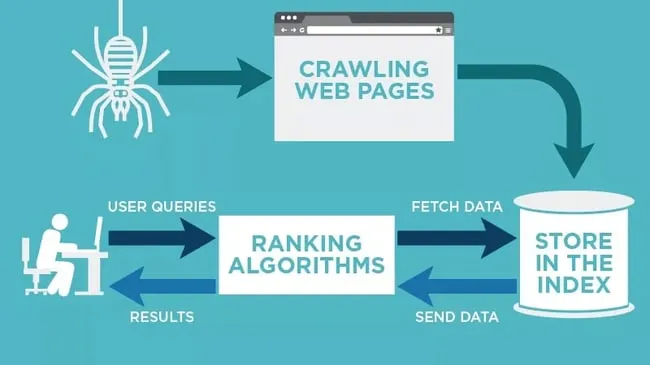
An overview of how web crawlers work (Image source: HubSpot)
This recursive process allows crawlers to browse across the complex web of interlinked pages and build a searchable index of the internet.
Types of Web Crawlers
There are several categories of web crawlers designed for different purposes:
- Search Engine Crawlers – The largest crawlers from Google, Bing, etc. that build massive indexes for web search.
- Vertical Crawlers – Focus on specific industries, topics or media types, e.g. job, local business, news, video, image crawlers.
- Feed Fetchers – Download syndicated feeds like RSS/Atom.
- Email Harvesters – Scrap websites for email addresses.
- Web Scrapers – Extract specific data from websites.
- Sitemaps Crawlers – Crawl submitted XML sitemaps to prioritize discovery.
- Archival Crawlers – Create archives of websites e.g. Wayback Machine.
- Malicious Crawlers – Unethically access sites e.g. scrapers, hacking bots.
- Personal Crawlers – Individuals crawl specific sites e.g. for research.
So in summary, there is a wide spectrum of crawler types serving different use cases beyond generalized web search.
What Makes a Good Crawler?

An effective web crawler should have the following characteristics:
- Scalability – Crawl the enormous web with limited resources.
- Speed – Crawl quickly without overloading websites.
- Breadth & Depth – Achieve broad coverage but also crawl deep pages.
- Polite – Honor robots.txt to avoid over-crawling.
- Refresh Rate – Revisit sites appropriately to keep index fresh.
- Fault Tolerance – Handle crashes and failures smoothly.
- Parallelization – Concurrent crawling for speed and efficiency.
- Cloud Optimization – Leverage the cloud for storage and computing resources.
- AI Integration – Incorporate AI for optimal crawl prioritization.
- Security – Prevent infiltration from hackers and spammers.
Building a crawler that balances all these facets is an extremely complex engineering challenge. Search engines invest tremendous resources into developing and refining their crawl technology.
Challenges in Web Crawling
While crawlers are invaluable, designing them involves overcoming some key challenges:
- Scale – The internet is massive with billions of pages. Crawling it efficiently is hugely challenging.
- Changing Content – Websites update frequently. Tracking these changes at scale is difficult.
- Hidden Content – Relevant content may be tucked away deep or behind forms. Tough for crawlers to discover.
- Duplicates – Pages with similar content but different URLs must be detected.
- Inaccessible Pages – Firewalls, limited-access and dynamic pages are hard to crawl.
- ** Crawl Overload** – Aggressive bots can overload servers with requests and get blacklisted.
- Cloaking & Doorway Pages – Tricky techniques used by some sites to manipulate crawlers.
- Spam – Crawlers must avoid indexing comment/forum spam and other junk content.
- Speed vs. Quality – Balancing comprehensive crawling with optimized performance is tricky.
Mastering these challenges involves constant crawler innovation and refinement.
Best Practices for Crawler Friendly Websites
As a website owner, you can also help search engine crawlers index your pages faster and more intelligently by following some best practices:
- Optimize Robots.txt – Give crawling directives without blocking large sections unnecessarily.
- Fix Broken Links & Errors – Crawlers struggle with dead links and failed pages.
- Enhance Site Architecture – Make information architecture and internal linkingcrawler-friendly.
- Simplify URL Structure – Avoid overly complex dynamic URLs if possible.
- Set Canonical Tags – Clarify duplicate content issues.
- Make Ajax Crawlerable – Ensure content loaded by JavaScript is indexable.
- Submit Sitemaps – Let crawlers discover new URLs efficiently via sitemaps.
- Use Descriptive Metadata – Quality page titles and meta descriptions improve indexing.
- Employ Structured Data – Formats like schema.org help crawlers understand content.
- Avoid Spam Techniques – Don’t try to fool crawlers with tricks like keyword stuffing.
- Enable Indexing – Allow search bots via meta tags and directives.
- Analyze Crawl Stats – Review search engine crawl reports to identifyissues.
By optimizing your website for web crawlers, you can improve search visibility, traffic and rankings.
The Future of Web Crawlers
Web crawling technology will continue advancing as the web grows more sophisticated. Here are some predicted trends:
- AI-Powered Crawling – Leveraging AI for optimized crawl planning and efficiency. Google is testing an AI-based crawler called HowNodes.
- Distributed Crawling – Coordinated crawling across multiple servers for scalability.
- Vertical Specific Crawlers – More advanced vertical crawlers tuned for niche data.
- JavaScript Crawling – Better crawling of complex JavaScript heavy sites.
- Accelerated Mobile Crawlers – Optimized crawling for the mobile web.
- Blockchain Crawlers – Crawling decentralized blockchain based networks.
- Voice Crawling – Indexing voice content for voice search.
- Visual Crawling – Beyond text to index and search visual content via computer vision.
Web crawlers must continuously evolve to provide users with comprehensive, fresh and relevant search results. Exciting crawler innovations lie ahead to keep pace with the dynamic web.
The Wrap
Web crawlers are the unsung heroes of search engines. Without their tireless work crawling across the maze of interlinked pages on the web, search engines would not be able to function and organize information for users.
Understanding how crawlers work provides valuable insights into improving search engine optimization and building crawler-friendly websites. As crawling technology continues maturing, it will open up new possibilities for better search and discovery across the vast internet.
FAQs about Web Crawlers
What are web crawlers javascript?
JavaScript crawlers are programs designed to index JavaScript heavy websites. They can render and execute JavaScript to crawl dynamic content loaded by JS. Examples include Googlebot, Bingbot, Screaming Frog SEO Spider.
What are web crawlers in search engine?
Search engine web crawlers are bots that browse the web to discover pages, extract information, and add it to the search engine’s index. Major search engines like Google and Bing rely on web crawlers to build their indexed database of web pages.
What are web crawlers examples?
Some examples of web crawlers are Googlebot, Bingbot, Yahoo! Slurp, Ask Jeeves Teoma, DuckDuckBot, YandexBot, Baidu Spider, Facebook External Hit, Twitterbot, Screaming Frog, and AhrefsBot.
What are web crawlers called?
Web crawlers are also referred to as robots, bots, spiders, wanderers, worms, walkers, scrapers, and web spiders. All these terms essentially mean automated programs that browse the World Wide Web in a methodical manner.
What are web crawlers and how does it work?
Web crawlers are programs that systematically browse the web by crawling from page to page, indexing information along the way. They start with a list of seed URLs, fetch page content, extract data like text and links, add info to a search index, and use links to find new pages to crawl.
Types of web crawlers
Some major types of web crawlers are search engine crawlers, vertical crawlers, feed fetchers, email harvesters, web scrapers, sitemaps crawlers, archival crawlers, malicious crawlers, and personal crawlers.
Web crawler tool
Some popular web crawler tools used for SEO, content analysis, data mining, and market research are Screaming Frog, ParseHub, MozBot, HubSpot Crawler, DiffBot, Import.io, and Phantombuster.
Web crawler is also known as
Web crawlers are also referred to as robots, bots, spiders, wanderers, worms, walkers, scrapers, and web spiders. All these terms essentially mean automated programs that browse the World Wide Web in a methodical manner.
What does a web crawler do?
A web crawler systematically browses the World Wide Web to index pages and content in a search engine’s database. Their main function is to enable efficient searching of the internet by discovering new pages, extracting information, and keeping indexes up to date.
What is an example of a web crawler?
Some examples of well-known web crawlers are Googlebot, Bingbot, Yahoo! Slurp, DuckDuckBot, Ask Jeeves Teoma, YandexBot, Facebook External Hit, Screaming Frog, and MozBot.
What are crawlers explained?
Crawlers, also called spiders or robots, are computer programs that browse the World Wide Web in an automated, methodical manner to index and search the internet. They crawl from page to page, grab information, follow links to discover new pages, and send data back to be organized in a search engine’s database.
What are Google’s web crawlers called?
Google’s primary web crawler is called Googlebot. It crawls billions of pages across the web to build Google’s search index. Other Google crawlers include the mobile Googlebot-Mobile, image crawler Googlebot-Image, and Google Adsbot.
What is the most active web crawler?
Googlebot is considered the most active and prolific web crawler today. With over 90% market share in search, Googlebot crawls trillions of pages across the internet to power Google Search results. Other very active crawlers are Bingbot, Baidu Spider, Yahoo! Slurp and YandexBot.
Is Google a web crawler or web scraper?
Google operates primarily as a web crawler, not a scraper. Googlebot discovers public web pages and indexes information from sites instead of scraping or copying content. However, Google does use focused scrapers to extract specific data like prices and events from websites.
Also read: 50+ High Paying Guest Posting Sites for Freelance Writers



{kind=link}